
Pandas
✔️pandas
import numpy as np
import pandas as pd데이터분석 라이브러리로, 행/열로 이루어진 데이터 객체를 다루기에 편리하다.
pandas에서 기본적으로 정의되는 자료 구조는 ①series ②dataframe 이다.
①series(vector): index와 value로 이루어진 데이터 타입
②dataframe(matrix): index, column, value로 이루어진 데이터 타입(table 형태)
✔️dataframe으로 로딩
read_csv(): CSV파일 포맷을 dataframe으로 변환하기 위한 api
CSV=column을 ' , '로 구분한 파일 포맷
data='csv파일 경로'
df=pd.read_csv(data)
sep 인자의 default 값은 sep= ' , '
탭으로 필드가 구분되어 있을 경우 sep=' \t '
df=pd.read_csv('csv파일 경로', sep='\t')
✔️dataframe 읽기
1. dataframe의 일부 데이터만 추출 (default 값은 '5')
- 맨 앞 일부 데이터만 (앞 부분만 추출해서 어떤 형식으로 되어있는지 확인해보는 것이 좋음)
df.head(3)- 맨 뒤 일부 데이터만
df.tail(4)
2. 행,열 개수를 튜플로 반환
df.shape
3. dataframe에서 고유값(=유일한 값) 얻기
ex. 개인과 직업으로 구성된 dataFrame에서 직접의 종류 나타낼 때
- 데이터 고유값의 종류(열에 있는 값들이 가능한 옵션의 종류)
df['특정 행 이름'].unique()- 데이터 고유값의 종류(unique한 것의 개수)
df['특정 행 이름'].nunique()- 값별로 데이터의 수 출력 (defalut 값으로 내림차순)(unique 항목에 대해서 몇 개가 있는지)
df['특정 행 이름'].value_counts()
df['특정 행 이름'].value_counts(ascending=True)
4. 시각화 하기
- pie chart
df.groupby(['특정 행 이름']).count()['row_id'].plot(kind='pie')- bar graph
df.groupby(['특정 행 이름']).count()['row_id'].plot(kind='bar')- pd.merge()
mergedata=pd.merge(데이터이름1, 데이터이름2, on='subject_id', how='inner')
mergedata.groupby(['특정 행 이름1', '특정 행 이름2']).size().unstack().plot(kind="bar", stacked=True)
✔️ex. diabetes.csv dataframe 기본적인 정보 얻기
📍 https://www.kaggle.com/datasets/uciml/pima-indians-diabetes-database
Pima Indians Diabetes Database
Predict the onset of diabetes based on diagnostic measures
www.kaggle.com
파이썬의 대표적인 시각화 도구: matplotlib, seaborn
seaborn은 matplotlib 대비 손쉽게 그래프를 그리고, 그래프 스타일 설정을 할 수 있다
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
data='diabetes.csv'
df=pd.read_csv(data)
1. data 검토
df.shape
df.head()
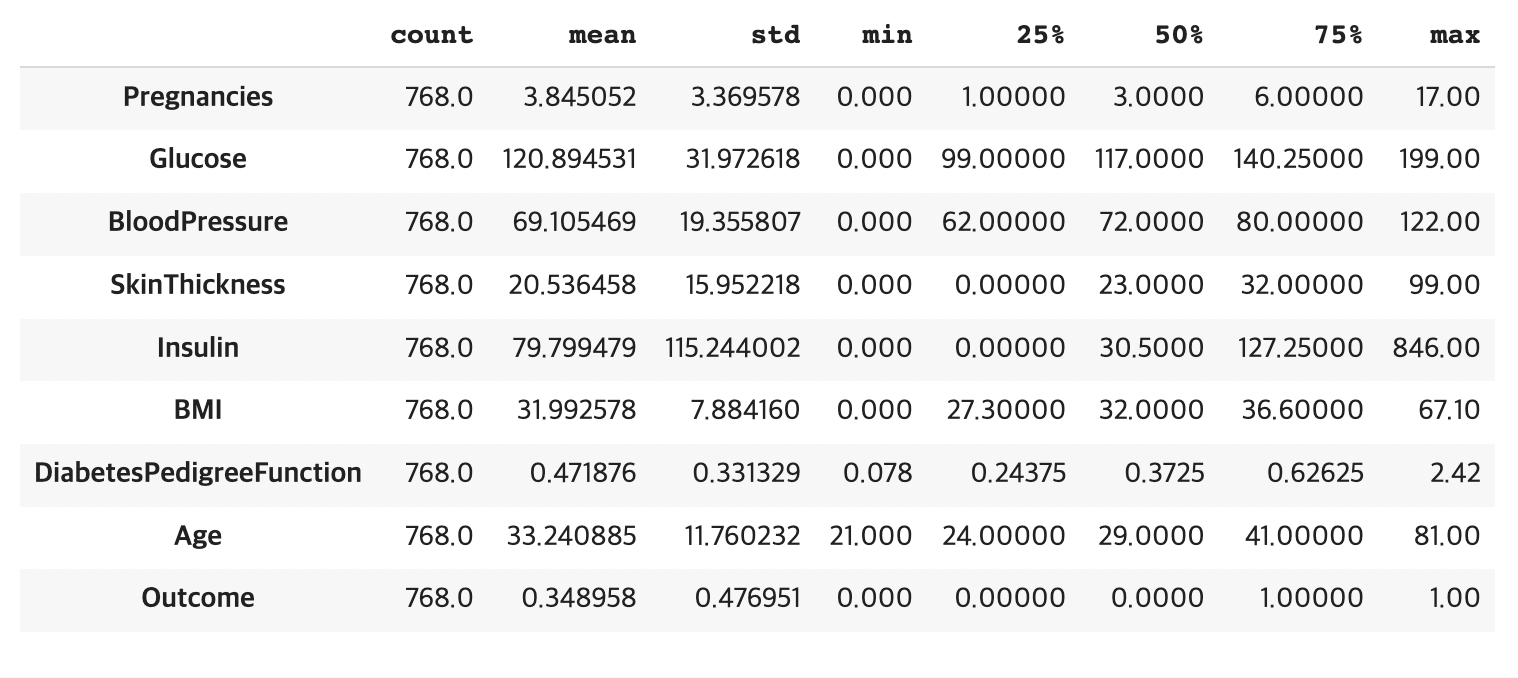
df.describe().transpose()
2. 시각화 (상관 관계를 알아보기 위함)
cor=df.corr()
sns.heatmap(cor)
plt.show()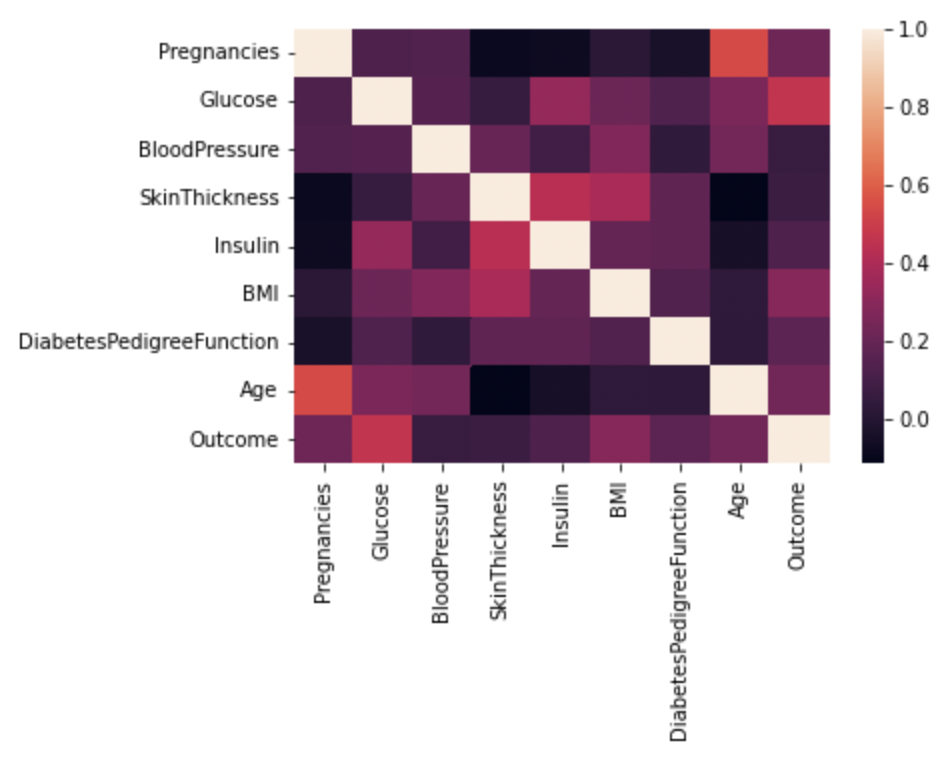
3. 시각화의 다른 형태 (두 변수의 조합에 대해서 그 관계를 알아보기 위함)
sns.pairplot(df, hue='Outcome')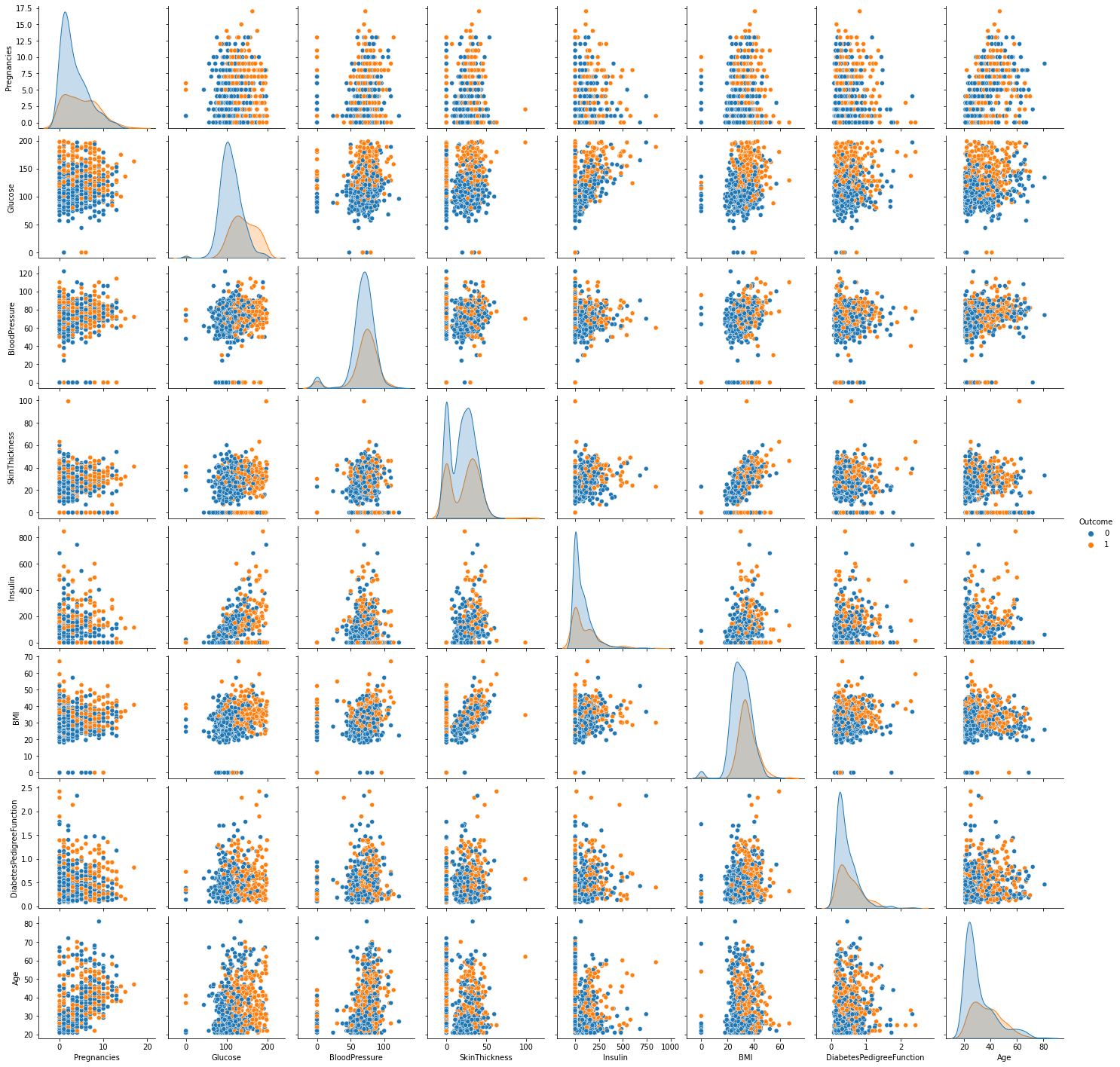
'📁 Data Analysis > 🖱 실습' 카테고리의 다른 글
| Titanic (0) | 2022.09.19 |
|---|---|
| Hospital (0) | 2022.09.14 |






